Exploring Personalized Neural Conversational Models
0.Abstract
对多种显著影响预测效果的因素做了评估,如预训练pretraining、嵌入训练embedding training、数据清理data cleaning、多样性重排序diversity-based raranking、评估设置evaluation setting(retrieval or generative evaluation),等等。
在更大的数据及上pretraining speaker embedding、bootstrapping word and speaker embedding可以显著提升效果(最高3点perplexity),使用MI提升回复多样性对提升ranking metrics(排名指标?)非常有用。
1.Introduction
2.Related Work
3.Models
介绍的baseline分为不考虑context/不考虑personalization/二者都不考虑
3.1 Notation
本文模型训练采用的是有多个对话者参与的数据集。
一场对话$C_i$是一个有序集,其中元素是由回合turn $D_i^j$和该回合的说话者speaker $S_i^j$组成的pair。i.e.$C_i={(D_i^1,S_i^1),(D_i^2,S_i^2),…,(D_i^n,S_i^n)}$。每个回合本身是对应说话者所说的words集合,$D_i^j={w^j_{i1},w^j_{i2},…,w^j_{in}}$。为了简洁,在对话中我们无视索引i.所有我们的语言模型基于每个时间步之前的信息预测下一个词的分布。先前不同模型的区别在于使用该回合之前信息的范围(the extent of information),而我们的工作是比较这些模型。
3.2 GRU
3.3 Baselines
本节所有语言模型,等号左边是相同的
3.3.1 Encoder-Decoder
不考虑说话人的信息,是dyadic(二元?)的。也就是说,下一个回复只依赖于当前的对话,独立于其他信息。
语言模型:
其中,$D^{-j}$指的是直到j的所有turns的集合。即$D^{-j}={D^1,D^2,…,D^{j-1}}$.Speakers $S^{-j}$同理。
3.3.2 Persona-only
[Li et al., 2016b]
引入说话人的信息作为encoder和decoder RNN两边的额外输入。
。因此,语言模型依赖于当前和之前回合的说话人,在生成新回复时考虑了人格。
3.3.3 Context-only
Hierarchical Recurrent Encoder-Decoder[Serban et al., 2016b]通过一个每回合更新自己隐藏层,且基于encoder-decoder RNNs的high level,context RNN捕捉上下文线索。但是没有包含任何人格信息。更多细节参考[Serban et al., 2015a].
注意下一个词依赖于所有之前的回合,进而通过历史保留上下文信息。但是在实践中,上下文被截断,只能考虑过去几个回合的信息。
3.4 CoPerHED Model
Context-aware, Persona-based Hierarchical Encoder-Decoder:混合了persona-based[Li et al., 2016b]和context-aware[Serban et al., 2016b]的神经交流模型。当前回合和之前回合的说话者信息被作为额外信息输入;使用额外的RNN在每个回合水平上总结信息。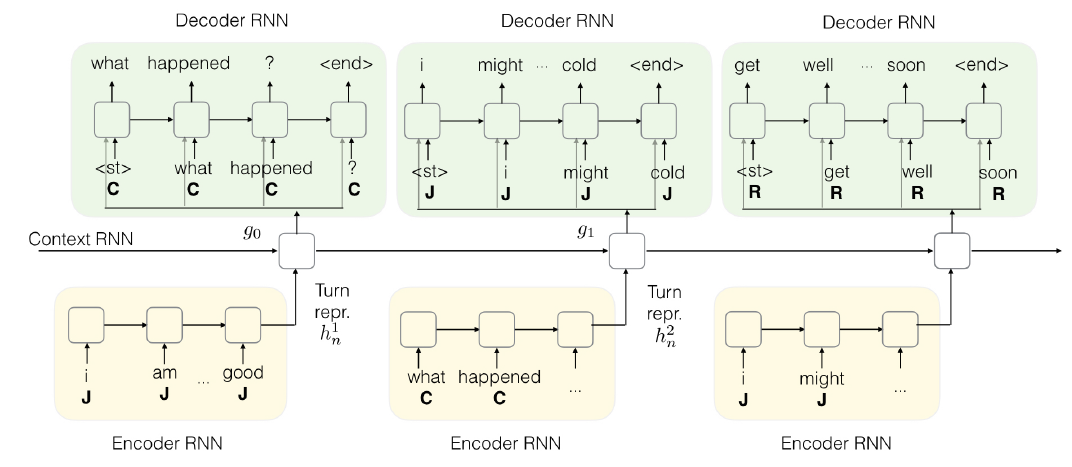
3.4.1 Encoder
第$j^{th}$回合的隐状态$h^j_t$由每个时间步输入一个词和当前speaker标记得到。所有words和speakers的reperesentation盒模型联合学习。
本回合说话者人格$s^j$对给定回合的所有时间步固定。
3.4.2 Context RNN
会话中每个回合的句子编码表示由context RNN处理。这有助于保留前一轮的相关信息,并作为预测response的上下文。与[Serban et al., 2016b]类似,CoPerHED由一组分层RNN构成。context RNN工作在turn-level,而language RNN(本例中为GRU)工作在every turn的word-level。
$g_j$表示$j^{th}$回合的context RNN的隐状态。
3.4.3 Decoder
输入:当前词语,当前回合speaker,context RNN的隐状态。$\hat{h}_t$表示decoder的隐状态:
4.Datasets
Movie-Dic
TV-Series
SubTle
5.Experiments
5.1 Data Preprocessing
5.2 Training
参数介绍。
- 网络:Encoder和Decoder都是两层GRU
- dropout:0.2
- Adam optimizer
- learning rate:0.001(1e-3),10个epoch结束时指数衰减到0.0001(1e-4),之后保持为常量
- 梯度剪裁[-5.0, 5.0]
- 结束条件:hold-out验证集的困惑度饱和
最优效果:
- word embedding size:300
- speaker embedding size:50
- encoder/decoder GRU 隐单元:300
- context GRU隐单元:50
5.3 Initialization
5.3.1 Bootstrap word embeddings
使用在大数据集上训练好的word2vec
5.3.2 Bootstrap speaker embeddings
使用人工特征初始化speaker embedding。对所有speaker,从训练数据中构建BOW词袋特征,并使用PCA降维。
5.3.3 Pre-train on SubTle dataset
在标注数据集上微调之前,先使用大规模的数据集预训练,所有speaker分配为$
5.3.4 Model Varients
5.4 Evaluation
Generation: 困惑度Perplexity
Retrieval: Recall@k
5.5 Promoting diversity using MI
[Li et al., 2016a],打分函数从似然likelihood变成互信息。
6.Results
7.Discussion and Conclusion
实验技巧:
- 在更大的数据集上预训练speaker embedding
- bootstrap word and speaker embedding
模型:
persona-based + context aware,即speaker embedding + context RNN
